Motivation
We’re in a community that petabytes of transactional data are stored at large clusters, usually partnered with Hadoop. To analyze such data, it’s popular to use interactive data mining tools (e.g. R, Zepplin) over the Hadoop data-space. Going with the technology buzz in big data over last decade, MapReduce acts as a reliable cluster computing frameworks for large scale data analytics. Writing parallel computations over MapReduce was getting easier with the introduction of many abstraction over cluster’s computing resources (i.e. cores, network bandwidth). But the lack of general abstraction over shared cluster memory was identified as a major limitation of former framework to deal with many iterative algorithms, where they naturally apply the same operation to multiple data items (e.g. k-means, page rank). Thus, the efficiency of such algorithms can be improved by sharing intermediate results over parallel computations (i.e. map-reduce). The rest of the article focuses on leveraging such computations over a distributed shared memory data-structure Resilient Distributed Datasets (RDD) which comes along with it’s own programming interface Apache Spark – a new born baby in the big data family.
Resilient Distributed Datasets
In general, RDDs are fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory. A RDD is immutable at it’s nature and can be only created via deterministic operations called transformations (i.e. map, filter and join). Transformations are lazy operations while actions launch a computation over RDD to return a value.
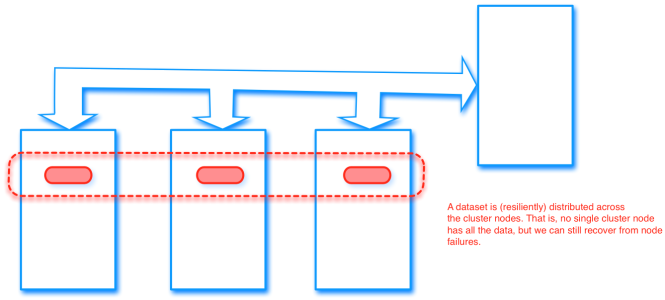
Further, users can indicate which RDDs they will reuse and choose a storage strategy for them (e.g., in-memory or disk storage). Partitions that do not fit in RAM can be stored on disk and will provide similar performance to current data-parallel systems.
Pros. and Cons.
Complementary, Spark supports data parallelism to partition the RDD over many cluster nodes. Then, Spark job scheduler send computation tasks (i.e. transformations) to nodes where the partitioned data resides. For example, an RDD representing an HDFS file has a partition for each block of the file and knows which machines each block is on. Meanwhile, the result of a map on this RDD has the same partitions, but applies the map function to the parent’s data when computing its elements. This is different than other cluster computing frameworks (e.g. MapReduce) that harness task parallelism instead of data.
Also RDDs provide an efficient fault tolerance than any other distributed data-structure, since they do not need to incur the overhead of checkpointing, as they can recover it’s own partition of data by recomputing the same transformations. The operation is supported by keeping the list of transformations as a lineage graph.
Working with RDD
In mean time, RDDs are optimized for reads, but not for bulk writes since they do not support fine grained updates. As an example RDDs are less efficient to use as a storage system for a web application. Also, they would be less suitable for applications that require multiple operations to perform over different iterations to the same set of elements.
On top of RDD
After the concept of RDD revolutionized the community of big data, many other platforms tend to adopt it and build a stack of tools to use.

BDAS
As shown at Figure, many big data computing frameworks are driven by RDDs. Thus, RDD acts as the unsung hero at many modern day machine learning platforms (e.g. Typesafe Reactive, Databrick cloud)
