We used have Singleton Design Pattern in our applications whenever it is needed. As we know that in singleton design pattern we can create only one instance and can access in the whole application. But in some cases, it will break the singleton behavior.There are mainly 3 concepts which can break singleton property of a singleton class in java. In ...
Microservices can have a positive impact on your enterprise. Therefore it is worth to know that, how to handle Microservice Architecture (MSA) and some Design Patterns for Microservices. General goals or principles for a microservice architecture. Here are the four goals to consider in Microservice Architecture approach [1].Reduce Cost: MSA will reduce the overall cost of designing, implementing, and maintaining ...
Last few years has been a great year for API Gateways and API companies. APIs (Application Programming Interfaces) are allowing businesses to expand beyond their enterprise boundaries to drive revenue through new business models. Larger enterprises are adopting API paradigm — developing many internal and external services that developers connect to in order to create user-facing products. As the number of APIs ...
kubectl (Kubernetes command-line tool) is to deploy and manage applications on Kubernetes. Using kubectl, you can inspect cluster resources; create, delete, and update components. NOTEYou must use a kubectl version that is within one minor version difference of your cluster. If not you may see errors as below 1. Download the latest release v1.13.0 using curl installed, use this ...
WSO2 Enterprise Integrator is shipped with a separate message broker profile (WSO2 MB). In this Post I will be using message broker profile in EI (6.3.0). 1) Setting up the message broker profile1.1) Copy the following JAR files from the <EI_HOME>/wso2/broker/client-lib/ directory to the <EI_HOME>/lib/ directory.andes-client-3.2.13.jargeronimo-jms_1.1_spec-1.1.0.wso2v1.jarorg.wso2.securevault-1.0.0-wso2v2.jar1.2) Open the <EI_HOME>/conf/jndi.properties file and add the following line after
When two or many applications want to exchange data, they do so by sending the data through a channel that connects the each others. The application sending the data may not know which application will receive the data, but by selecting a particular channel to send the data on, the sender knows that the receiver will be one that is ...
Microservices are going completely over the enterprise and changed the way people write software within an enterprise ecosystem. Let build you microservices with msf4j for Auto Mobile. 1) Create msf4j using apache archetype with below commandmvn archetype:generate -DarchetypeGroupId=org.wso2.msf4j -DarchetypeArtifactId=msf4j-microservice -DarchetypeVersion=1.0.0 -DgroupId=org.example -DartifactId=automobile -Dversion=0.1-SNAPSHOT -Dpackage=org.example.service -DserviceClass=AutomobileService2) Open it on ID
The SMPP inbound endpoint allows you to consume messages from SMSC via WSO2 ESB OR EI. 1. Start SMSC2. Create custom inbound end point with below parameter. (Make sure you pick correct system-id and password correct for your SMSC)3. Create Sequence for Inbound EP.4. Once ESB or EI start.you will start see SMSC log ESB log will contains
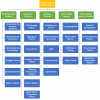
WSO2 APIM ComponentsWSO2 API Manager includes five main components as the Publisher, Store, Gateway, Traffic Manager and Key Manager.API Gateway - responsible for securing, protecting, managing, and scaling API calls. it intercepts API requests and applies policies such as throttling and security checks. It is also instrumental in gathering API usage statistics. API Store - provides a space for consumers ...
1. Introduction to SMPP and SMSCSMPP - Short Message Peer to Peer protocol is an open, industry standard protocol designed to provide a flexible data communications interface for transfer of short message data between a Message Center, such as a Short Message Service Centre (SMSC), GSM Unstructured Supplementary Services Data (USSD) Server or other type of Message Center and a ...
There is REST Back-End end-point in Vehicle registration services as belowGET /car?name=prius HTTP/1.1Host: localhost:8080color: WhiteCompany need to expose it 3rd part companies and above End-point should not change as internal services are using it.GET /new-car/vitz/white/ HTTP/1.1Host: localhost:8280Server is contain with wso2 ESB or EI. Then you can it easily without using any property mediators even. If you see mapping will ...
Estimation for Software project development is the process of predicting the most realistic amount of effort (expressed in terms of person-hours or money) required to develop or maintain software based on incomplete, uncertain and noisy input. Project managers, stakeholders, and staff members can use software metrics to more accurately estimate progress toward project milestones, especially when historical or trend data ...
In this post give some basic on JAVA Stream API which is added in Java 8. It works very well in conjunction with lambda expressions. Pipeline of stream operations can manipulate data by performing operations like search, filter, count, sort, etc. A stream pipeline consists of a source such as an array, a collection, a generator function, an I/O channel. ...
The Lifecycle Management(LCM) plays a major role in SOA Governance. WSO2 Governance Registry Lifecycle Management supports access control at multiple levels in lifecycle state.1. Permissions1.1 Check items with permissions configuration<permissions> <permission roles=""/></permissions>1.2 State Transitions by transitionPermission configuration<data name="transitionPermission"> <permission forEvent="" roles=""/></data>2. Validations2.1 Check items by he validations configu
Enterprise Data Integration is a broad term used in the integration landscape to connect multiple Enterprise applications and hardware systems within an organization. All these enterprise data integration lead to achieve to remove the complexity by simplifying data management as a whole.Unified Data Management ArchitectureUnified Data Management Architecture offers reliability and performance of a data warehouse, real-time and low-latency characteristics ...
Post is very basic one, Since Talend is all about data integration. Finding a BigDecimal [1] in such data set is very common. BigDecimal VS Doubles A BigDecimal is an exact way of representing numbers. A Double has a certain precision. Working with doubles of various magnitudes (say d1=1000.0 and d2=0.001) could result in the 0.001 being dropped all together ...
Vehicles registration services using REST services on government TAX department system. That REST services give the TAX information for the Vehicle. {"Tax": {"Amount": 58963}}Vehicles registration Depart planning to extend the service and expose as below.{ "VechileRegistrationTAX": 58963, "Currency": "LKR"}They will need transformation and valid the respond they collect from the TAX department. They will need simple proxy for this. <!—To ...
Data integration is the combination of technical and business processes used to combine data from disparate sources into meaningful and valuable information. Today some systems may store data in a denormalized form and data integration tools able handle those. In this blog post Talend will be used to show case handling simple denormalized data set file.For example, system stores state ...
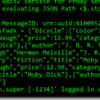
There is few thing that make my work enjoyable with WSO2 ESB as it provides support for JavaScript Object Notation (JSON) payloads in messages. It is not very new feature and it old feature. It supports JSON message building Converting a payload between XML and JSON Accessing content on JSON payloads Logging JSON payloads Constructing and transforming JSON payloads Troubleshooting, ...
Working on an Alienvault IDS system or OSSIM you can come across over huge amount of alarms are created will system migrations. use the ossim-db command:> ossim-db use the alienvault database:> USE alienvault Check for Alarm tables >SHOW TABLES LIKE 'alarm%'; Get table description >DESCRIBE alarm; Get the number of records in a table 'alarm'. >SELECT COUNT(*) FROM alarm; Listing ...